Welcome to Creating a Machine Learning Model. This section will describe how to create the machine learning model after adding the indicator or instrument data you would like to use. For help with programming the machine learning strategy please click on the Programming Your Machine Learning Strategy.
If you would prefer, there is an online video that goes over creating machine learning models as well. Please click on the video picture below to go to the Deep Signal Technologies YouTube Channel.

The first step is to make sure, the strategy compiles before creating the machine learning model. Please see the steps in programming your machine learning model for compiling your code.
If the code compiles without errors then the next step is to create a new machine learning model.
|
Hint: If you are trading futures such as ES or NQ then you will need to download continuous contracts for the instrument. This means that there any expired contract data will rollover to the next period. If you are creating a model with a contract period such as ES 03-22 then only 3 months of data will be used for either creating the model or trying to predict a long or short signal in that time period. If you would like more information on setting up continuous contracts, here is a link to a NinjaTrader topic: |
|
|
In the NinjaTrader Control Center's main menu go to New -> Strategy Analyzer.
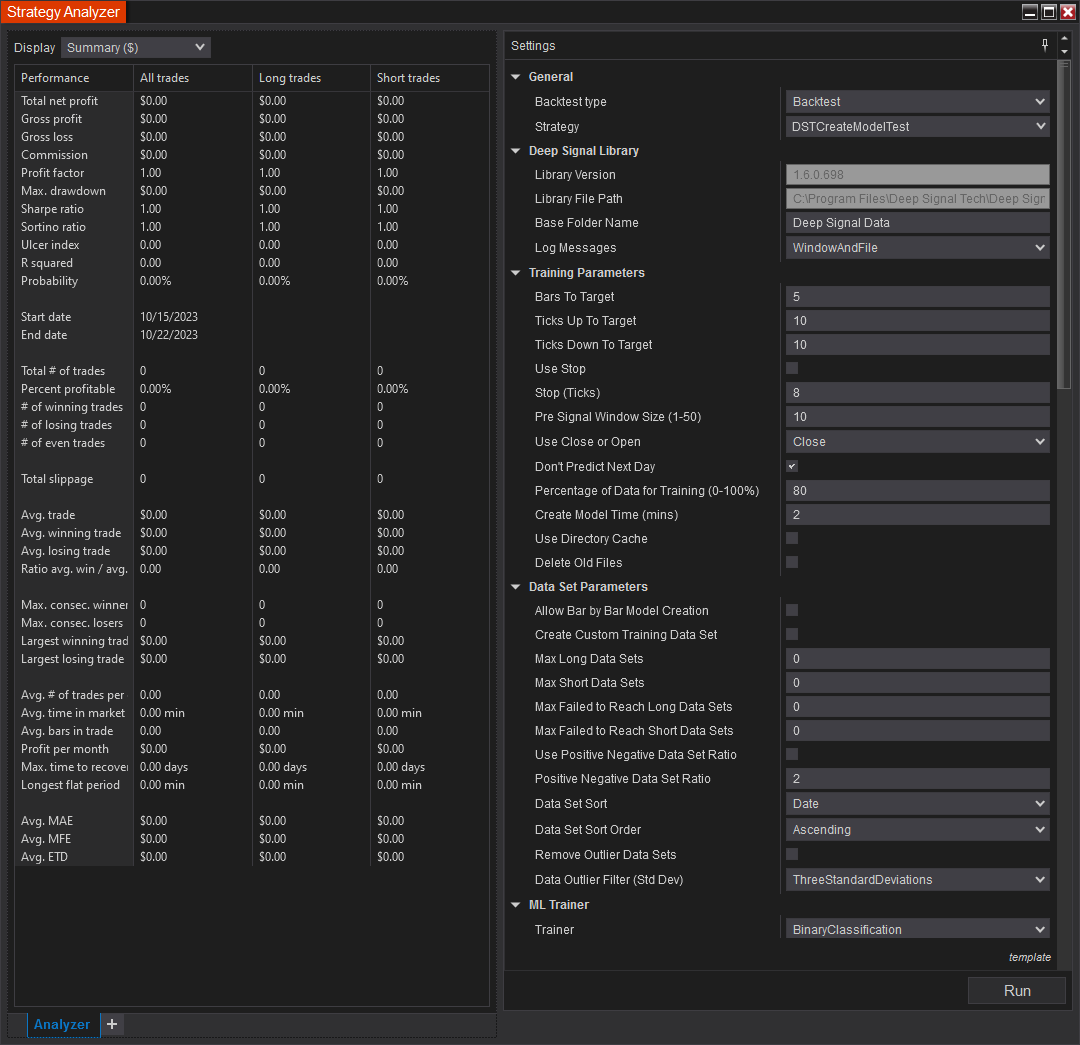
Here is a list of settings that the user can adjust for the Deep Signal Library. It's separated by main groups such as General, Deep Signal Library and Training Parameters.
General Settings
- Backtest type - Make sure Backtest type is set to Backtest for creating a new machine learning strategy.
- Strategy - Select which strategy you would to use for creating a machine learning strategy. For our DST example, please select the DSTCreateModelTest in the dropdown.
Deep Signal Library Settings
- Library Version - The current installed version of the Deep Signal Library
- Library File Path - The installation folder for the Deep Signal Library
- Base Folder Name - New machine learning strategies will be created in a subfolder of the NinjaTrader folder with this name. If the ML Base Folder Name is ML Data then new machine learning strategies will be created in Documents\NinjaTrader 8\ML Data.
- Log Messages - There are four different selections. If Window Only is selected then the output from the log will be to the NinjaScript Output window. If File is selected, messages from the Deep Signal Library will be sent to the log.txt file in the Documents\NinjaTrader 8\ML Data\log folder. Please note messages will be automatically sent to the NinjaScript Output window (NinjaTrader Control Center -> New -> NinjaScript Output)
Training Parameters
- Bars To Target - This is the number of bars that the machine learning model will use with Ticks Up To Target or Ticks Down To Target to see if the price (Open or Close) for the strategy makes it to a profit target. As an example if the Bars To Target is 5 and Ticks Up To Target is 10, then the machine learning model will use that window of data for creating a machine learning model if the price of the trained instrument goes up 10 ticks within 5 bars.
- Ticks Up To Target - This is the number of ticks up to look for in Bars To Target bars. If the instrument goes up the number of ticks set in Ticks Up To Target within the number of bars set in Bars To Target, the window of data will be used for creating a machine learning model for long trades.
- Ticks Down To Target - This is the number of ticks down to look for in Bars To Target bars. If the instrument goes down the number of ticks set in Ticks Down To Target within the number of bars set in Bars To Target, the window of data will be used for creating a machine learning model for short trades.
- Use Stop - If this is checked then when the DST Library creates a new machine learning library, it will use the Stock (Ticks) parameter as a Stop Market
- Stop (Ticks) - If Use Stop is checked then this is the Stop value in ticks.
- Pre Signal Window Size (1-50) - This value allows the user to change the number of bars of data to use for creating a machine learning model. It is the number of bars that is captured before the user sees the long or short signal. Please read the Welcome Page for more information regarding the Pre Signal Window Size and a visual chart that shows how it is used.
- Use Close or Open - The user may choose to use either the open value of a bar or the close value for the bar to help determine what values to use for building the machine learning model.
- Don't Predict Next Day - If Don't Predict Next Day is checked then if we don't allow a model prediction data window that rolls into a new day. This prevents having data from a previous day (for example, the last few bars of the day) being used to feed the machine learning model of the next day. This is checked by default.
- Percentage of Data for Training (0-100%) - The percentage (0-100%) of the data to be used for training the model, the remaining percentage will be used for testing.
- Create Model Time (mins) - The number of minutes we want to train the model. This is an approximation and may vary.
- Use Directory Cache - If checked, when creating a new machine learning model, the DST Library will use a temporary folder to save experiment results. If not checked, the dST Library will use memory to store experiment results. Note, for large data sets and longer training times this may consume large amounts of memory on your computer.
- Delete Old Files - If checked, after a model is trained, the unnecessary data files will be deleted. This will save megabytes of hard drive space.
ML Trainer Parameters
- Trainer - The Trainer parameter determines which types of algorithms to use when training the model. These are the following types of trainers available:
- Binary Classification - Binary Classification is a type of classification model that have two label of classes. For the Deep Signal Library, the long and short signals are divided into their own models with a dataset that contains data that reached a profit target and data that failed to reach a profit target.
- Regression - A regression model is a statistical technique that estimates the relationship between a dependent variable and one or more independent (explanatory) variables using a function. The function can be a line or a plane depending on the number of independent variables.
- Multiclass Classification - A Multiclass classification is a classification task with two or more classes. The Deep Signal Library uses two classes, one for data sets that have reached a profit target and those that have failed to reach a profit target.
- Optimizing Metric - The Optimizing Metric's droplist will change depending on the Trainer that is selected. When a machine learning model is created it will use this optimizing metric as the basis for the model's performance.
- Binary Classification Metrics - The following are metrics that are passed to the library when training a model. The algorithm will try to optimize for the selected metric. The default is the F1 Score.
- Accuracy - Gets the accuracy of a classifier which is the proportion of correct predictions in the test set.
- AreaUnderPrecisionRecallCurve - Gets the area under the precision/recall curve of the classifier.
- UnderRocCurve - Gets the area under the ROC curve.
Remarks: The area under the ROC curve is equal to the probability that the classifier ranks a randomly chosen positive instance higher than a randomly chosen negative one (assuming 'positive' ranks higher than 'negative'). Area under the ROC curve ranges between 0 and 1, with a value closer to 1 indicating a better model.
- ConfusionMatrix - The confusion matrix giving the counts of the true positives, true negatives, false positives and false negatives for the two classes of data.
- F1Score - Gets the F1 score of the classifier, which is a measure of the classifier's quality considering both precision and recall.
Remarks: F1 score is the harmonic mean of precision and recall: 2 * precision * recall / (precision + recall). F1 ranges between 0 and 1, with a value of 1 indicating perfect precision and recall.
- NegativePrecision - Gets the negative precision of a classifier which is the proportion of correctly predicted negative instances among all the negative predictions (i.e., the number of negative instances predicted as negative, divided by the total number of instances predicted as negative).
- Negative Recall - Gets the negative recall of a classifier which is the proportion of correctly predicted negative instances among all the negative instances (i.e., the number of negative instances predicted as negative, divided by the total number of negative instances).
- PositivePrecision - Gets the positive precision of a classifier which is the proportion of correctly predicted positive instances among all the positive predictions (i.e., the number of positive instances predicted as positive, divided by the total number of instances predicted as positive).
- PositiveRecall - Gets the positive recall of a classifier which is the proportion of correctly predicted positive instances among all the positive instances (i.e., the number of positive instances predicted as positive, divided by the total number of positive instances).
- Regression Metrics - The following are metrics that are passed to the library when training a model. The algorithm will try to optimize based on the selected metric. The default is the F1 Score.
- MeanAbsoluteError - Gets the absolute loss of the model
Remarks: The absolute loss is defined as $L1 = \frac{1}{m} \ sum_{i = 1}^m | y_i - \hat{y}_i|$, where $m$ is the number of instances in the test set, $\hat{y}_i$ are the predicted labels for each instance, and $y_i$ are the correct labels of each instance. L1 loss is a non-negative, decreasing metric. Smaller values indicate a better model with respect to this metric.
- MeanSquaredError - Gets the squared loss of the model
Remarks: The squared loss is defined as $L2 = \frac{1}{m} \sum_{i = 1}^m (y_i - \hat{y}_i)^2$, where $m$ is the number of instances in the test set, \hat{y}_i are the predicted labels for each instance, and y_i are the correct labels of each instance. L2 loss is a non-negative, decreasing metric. Smaller values indicate a better model with respect to this metric.
- RootMeanSquaredError - Gets the root mean square loss (or RMS) which is the square root of the L2 loss
- RSquared - Gets the R-squared value of the model, which is also known as the coefficient of determination. R-Squared closer to 1 indicates a better fitted model.
- Multiclass Classification Metrics - The following are metrics that are passed to the library when training a model. The algorithm will try to optimize for the selected metric. The default is the F1 Score.
- LogLoss - Gets the average log-loss of the classifier. Log-loss measures the performance of a classifier with respect to how much the predicted probabilities diverge from the true class label. Lower log-loss indicates a better model. A perfect model, which predicts a probability of 1 for the true class, will have a log-loss of 0.
- LogLossReduction - Gets the log-loss reduction (also known as relative log-loss, or reduction in information gain - RIG) of the classifier. It gives a measure of how much a model improves on a model that gives random predictions. Log-loss reduction closer to 1 indicates a better model.
- MacroAccuracy - Gets the macro-average accuracy of the model.
Remarks: The macro-average is the average accuracy at the class level. The accuracy for each class is computed and the macro-accuracy is the average of these accuracies. The macro-average metric gives the same weight to each class, no matter how many instances from that class the dataset contains.
- MicroAccuracy - Gets the micro-average accuracy of the model.
Remarks: The micro-average is the fraction of instances predicted correctly across all classes. Micro-average can be a more useful metric than macro-average if class imbalance is suspected (i.e. one class has many more instances than the rest).
- TopKAccuracy - Convenience method for "TopKAccuracyForAllK[TopKPredictionCount - 1]". If TopKPredictionCount is positive, this is the relative number of examples where the true label is one of the top K predicted labels by the predictor.
- Trainer Selection - The user can choose whether to only train a new machine learning model with certain trainers or use all trainers available. Change the selection to SelectTrainers in order to select which trainers you would like to use.
Data Set Parameters
- Allow Bar by Bar Model Creation - If true, when training a new model and model finds a profit target, the Deep Signal Library will only advance one bar instead of moving ahead the total of bars to target plus window size in bars.
- Create Custom Training Data Set - If true, allow the user to add their own data windows for training a machine learning model. This will override the existing functionality and only data windows added via DSTAddLongDataWindow, DSTAddShortDataWindow, DSTAddFailedLongDataWindow and DSTAddFailedShortDataWindow will be used in training. Please see the Creating Custom Data Sets section for more information.
- Max Long Data Sets - When creating a new machine learning model, set this value to something other than 0 to set the maximum number of long profit target data sets to be used in training a model. If set to 0, the Deep Signal Library will use the total number of data sets found.
- Max Short Data Sets - When creating a new machine learning model, set this value to something other than 0 to set the maximum number of short profit target data sets to be used in training a model. If set to 0, the Deep Signal Library will use the total number of data sets found.
- Max Failed to Reach Long Data Sets - When creating a new machine learning model, set this value to something other than 0 to set the maximum number of failed to reach profit target data sets for long trades in training a model. If set to 0, the Deep Signal Library will use the total number of data sets found.
- Max Failed to Reach Short Data Sets - When creating a new machine learning model, set this value to something other than 0 to set the maximum number of failed to reach profit target data sets for short trades in training a model. If set to 0, the Deep Signal Library will use the total number of data sets found.
- Use Positive Negative Data Set Ratio - If checked, will ignore any maximum short or long data sets above and automatically set the max short or long data sets based on ratio. The ratio is based on Profit Target Reached/Profit Target Not Reached.
- Positive Negative Data Set Ratio - The ratio of Profit Target Reached/Profit Target Not Reached data sets that get set when creating a model. For example, if the ratio is set to 2, then the total Profit Target Reached data sets will be twice that of Profit Target Not Reached.
- Data Set Sort - This feature allows the user to sort the data sets that get fed into the machine learning models by Date or by Profit Target. This feature used in combination with either setting Max Long Data Sets or Max Short Data Sets will truncate unwanted data set entries. This feature can also be used with Use Positive Negative Data Set Ratio to help balance data sets.
- Data Set Sort Order - This will sort the Data Set Sort by either Ascending or Descending.
- Remove Outlier Data Sets - If checked, the library will remove data sets in which their potential profit target in ticks is above or below the average plus/minus the standard deviation of the potential profit target in ticks for the signal bar.
- Data Outlier Filter (Std Dev) - The multiple of standard deviations that will be used to filter outlier data sets.
The Data Series, Time Frame and Setup Parameters are NinjaTrader parameters for choosing which instrument and which time frames you would like to use for creating the machine learning model. Please choose which instrument and time frames you would like to use for creating a model and click on the Run button. When the Run button is pressed a progress dialog will pop up and show the progress for creating a new model.
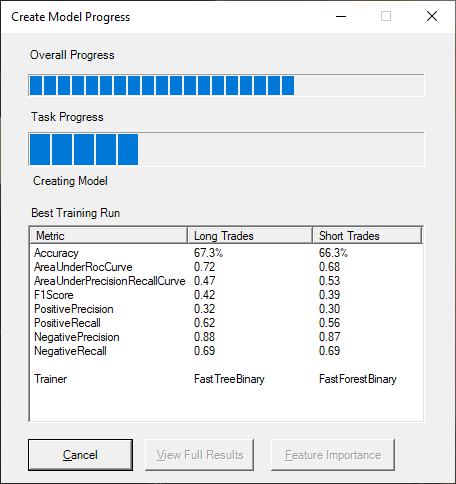
After the model has been trained the View Full Results button will be available to click on and view more details on the training run.
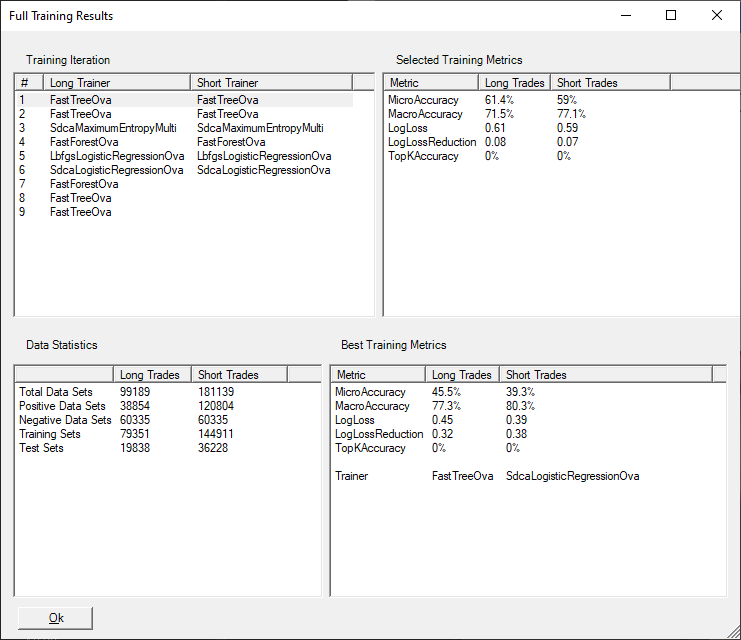
Selecting various training iterations on the left side of the window will show the training metrics for that training run. The Data statistics below will show the total data sets of each type. Positive Data Sets are the data sets that have reached a profit target. Negative Data Sets are those in which the price has failed to reach a profit target. The Training Sets numbers are the total data sets used for training a machine learning model and the test sets are data sets that are used for testing the model.
|
Hint: Before clicking on the Run button, we may want to open up the NinjaScript Output window by going to the NinjaTrader Control Center -> New -> NinjaScript Output. This will provide information regarding the progress of creating the machine learning model. |
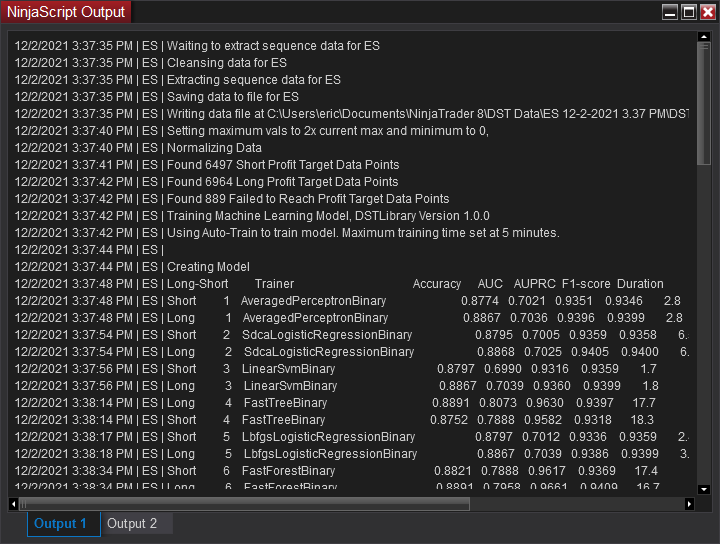
The process of creating a new machine learning model will create data files from the backtest data, cleanse the data of bad or missing ticks, normalize the data and finally will optimally train the model based on the chosen classification metric. The Microsoft ML.Net library will try several different machine learning algorithms to find the best suited algorithm based on the data set and classification metric.
The model results is also stored in the same folder as the model files in a file called DST.Model.Results.txt.
If the model results looks satisfactory then the next step is Programming For Predicting With New Model. If the model does not meet your needs then try changing some of the parameters and/or changing the Create Model Time to a larger number of minutes.
Futures, foreign currency and options trading contains substantial risk and is not for every investor. An investor could potentially lose all or more than the initial investment. Risk capital is money that can be lost without jeopardizing ones financial security or lifestyle. Only risk capital should be used for trading and only those with sufficient risk capital should consider trading. Past performance is not necessarily indicative of future results.